

مقیاس پذیری سرور یعنی توانایی یک سیستم جهت مدیریت افزایش ترافیک کاربران یک وب سایت، بدون آنکه کاربران متوجه هرگونه تغییری در سیستم شوند. فناوری بلاک چین هم با مشکلاتی از نظر مقیاس پذیری روبرو است که باعث شده تا برخی از بلاک چین ها برای تایید تراکنش های خود به زمان زیادی نیاز داشته باشند. در این مقاله از فکت کوینز قصد داریم شما را با تفاوت ها و شباهت های مقیاس پذیری در حوزه های مختلف آشنا کنیم.
مقیاس پذیری سرور چیست؟
مقیاس پذیری سرور یعنی توانایی یک سیستم جهت مدیریت افزایش ترافیک کاربران یک وب سایت، بدون آنکه کاربران متوجه هیچگونه تغییری در سیستم نشده و در ضمن کیفیت تجربه کاربری (UX) وب سایت نیز حفظ شود. از این رو در این مطلب از فکت کوینز قصد داریم تا به مفهوم مقیاس پذیری پرداخته و تلاش کنیم تا به سوالاتی همچون چیستی، علت نیاز به مقیاس پذیری، انواع مختلف آن و همچنین نحوه پیاده سازی آن پاسخ دهیم.

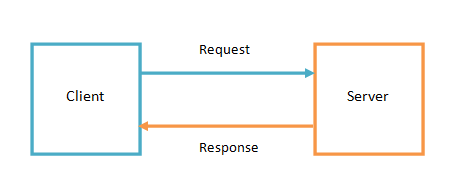
تصور کنید یک قطعه کد بر روی رایانه شما در حال اجرا است. مردم به کد شما نگاه کرده و آن را مفید میدانند و آماده هستند تا برای دسترسی و استفاده از آن هزینه ای را نیز پرداخت کنند. در حقیقت کاری که شما در اینجا انجام خواهید داد این است که یک API ایجاد کرده و نقاط پایانی را پیکربندی کرده تا کاربران قادر باشند که با آن ارتباط برقرار کنند. از طرفی، کاربران یک درخواست برای شما ارسال می کنند و سرور شما به آنها پاسخ مناسبی ارائه می دهد. در این بین، از آنجایی که در ازای این سرویسی که ارائه می دهید، مبلغی را دریافت می کنید، پس تمایل دارید که هیچوقت این سروس از کار نیفتد.
اما تصور کنید که در صورت قطعی برق، چه اتفاقی برای سرور شما خواهد افتاد؟ یا اینکه چه اتفاقی رخ می دهد اگر وب سایت شما تنها در عرض یک شب به موفقیت بزرگی برسد و پس از آن قادر به رسیدگی به حجم بالایی از درخواست ها از سوی کاربران نباشید. شما با چنین شرایطی چطور کنار می آیید.
بصورت کلی در چنین شرایطی، 2 راه حل پیش روی افراد قرار می گیرد:
- یک رایانه قدرتمند تر خریداری کنید
- به تعداد رایانه های پشتیبانی کننده از سرور خود اضافه کنید
اساساً این توانایی جهت خرید رایانه های قدرتمند یا خرید رایانه ها بیشتر جهت توانمند سازی سروز، به عنوان مفهومی تحت عنوان مقیاس پذیری سرور شناخته می شود. حال اینکه به راه حل اول، مقیاس پذیری عمودی گفهت می شود که طی آن، ما تنها اقدام به خرید یک رایانه قدرتمند تر کرده و بدین ترتیب ابعاد منابع خود را افزایش می دهیم. اما مورد دوم بنام مقیاس پذیری افقی شناخته می شود که در آن ما رایانه های بیشتری را با پیکربندی یکسان خریداری کرده که همه آنها کارهای مشابهی را انجام خواهند دارد. در واقع در مورد دوم، کاری که ما انجام میدهیم این است که اساساً مقیاسپذیری سیستم را افزایش داده و باعث میشویم تا سیستم ما به درخواستهای بیشتر و بیشتری رسیدگی کند.
بصورت کلی اگر افزودن منابع جهت تسهیل افزونگی یا فراوانی (redundancy)، منجر به کاهش یا از دست دادن مطلوبیت عملکرد نشود، در اینجا گفته میشود که یک سرویس همواره آنلاین، مقیاسپذیر است.
انواع مقیاس پذیری
حال قصد داریم تا بطور خلاصه خصوصیات مربوط به مقیاس پذیری های افقی و عمودی را بیان کنیم.
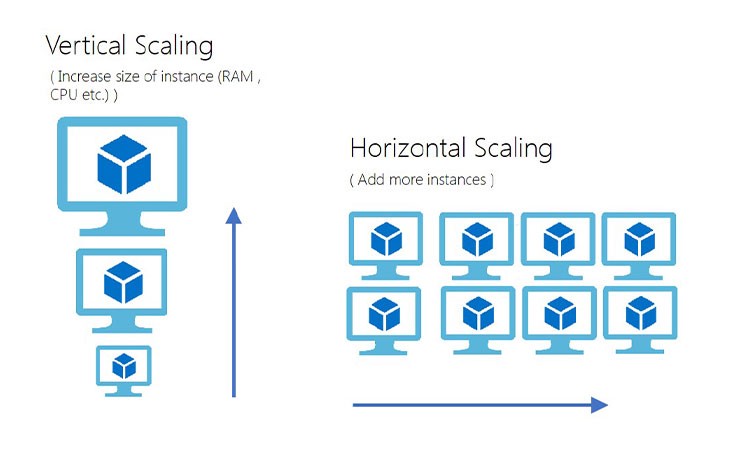
مقیاس پذیری افقی
- نیازمند تعادل بار است.
- انعطاف پذیر: هیچ نقطه شکست واحدی وجود ندارد.
- تماس های شبکه بین دو رایانه (RPC) کند هستند.
- همواره با مشکل سازگاری داده ها روبرو است.
- هیچ محدودیت سخت افزاری وجود ندارد، یعنی مقیاس آن به خوبی افزایش می یابد.
مقیاس پذیری عمودی
- نیازی به تعادل بار نیست.
- دارای نقطه شکست واحد
- ارتباط بین سرویس ها از طریق IPC (ارتباطات بین فرآیندی یا Intra Process Connection) که اتفاقاً بسیار سریع است، رخ می دهد.
- سازگاری داده: حافظه پنهان (Cache) سازگار داشته و هیچگونه خواندن و نوشتن کثیفی (Dirty Read and Write) در آن وجود ندارد.
- محدودیت سخت افزاری: نمی توان از 100% توانایی محاسباتی خود فراتر رفت. در واقع در این مقیاس پذیری شاهد محدودیت سخت افزاری هستیم.
مطلب مفید:مقیاس پذیری در بلاک چین به چه معنا است؟
چرا مقیاس پذیری تا این حد دشوار است؟
این موضوع از این جهت است که نمیتوان مقیاس پذیری سرور را به عنوان مفهومی جهت پیاده سازی بر روی سیستم هایی که در آینده قرار است مورد استفاده قرار گیرند، بکار برد. در واقع این امر مستلزم این است که برنامه و پلتفرمها با در نظر گرفتن مقیاس پذیری طراحی شوند؛ به گونهای که افزودن منابع و افزونگی، منجر به بهبود عملکرد سیستم شده و تأثیر نامطلوبی بر آن نداشته باشد.
از طرفی مشکل دیگر این است که رشد یک سیستم از طریق مقیاسپذیری افقی منجر به سیستمی میشود که باید با ناهمگنی مطابقت داشته باشد؛ یعنی برخی از گرهها (نودها) میتوانند بهتر عمل کرده و در نتیجه تنوع در سختافزارهای موجود، دادههای بیشتری را در خود ذخیره کنند. نتیجتاً اینکه سیستم های نسل بعدی به مراتب قدرتمندتر و از نظر اقتصادی مقرون به صرفه تر هستند و بایستی مقیاس پذیری سرور را همگام با طراحی و ساخت آنها به قابلیت های آنها اضافه کرد. این یعنی فقط در صورتی می توانیم به یک مقیاس پذیری مطلوب دست پیدا کنیم که سیستم های خود را به گونه ای طراحی و مهندسی کنیم که مقیاس پذیری سرور را در آنها نظر بگیریم.
اما نکته مهمی که تا بدین جا به آن پی بردیم این است که نمیتوانیم این مشکل را تنها با صرف هزینه بر روی منابع و افزایش آنها حل کنیم. در حقیقت، مقیاس پذیری سرور افقی پذیرش این واقعیت است که در نهایت یک سقف میعنی وجود خواهد داشت که با رسیدن به این محدودیت، ما قادر نخواهیم بود تا محاسبات بیشتری را انجام دهیم. پس چرا سیستم خود را به گونهای طراحی نکنیم که با تهیه یک سری رایانه های ارزانتر و سریعتر، این محدودیت را از میان ببریم؟
بهای دستیابی به مقیاس پذیری سرور چیست؟
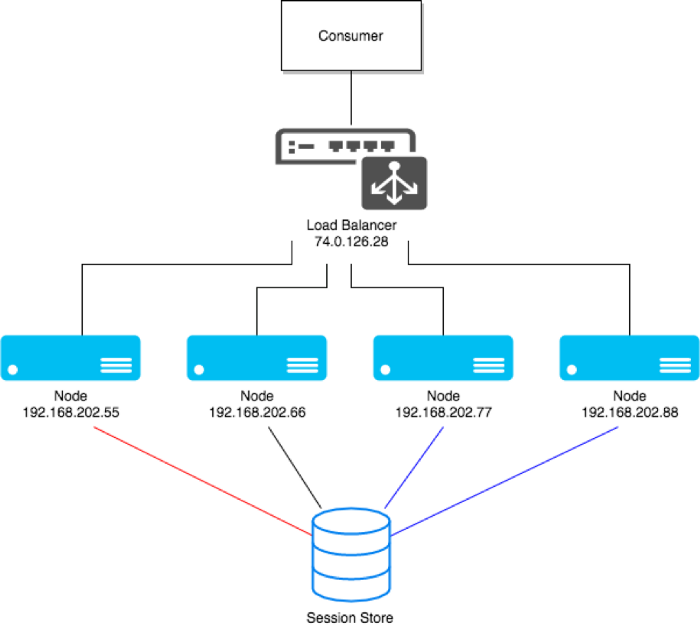
اساساً داستان بسیار سادهتر می شد اگر ما یک سرور واحد با آدرس IP و نام میزبان یا هاست (Host) مرتبط با آن سرور/ماشین بخصوص داشتیم که نام آن سرور الف بود. حال اگر وبسایت ما به سرعت و یک شبه رشد می کرد و ما در مسیر پذیرش مقیاس پذیری سرور افقی، چندین سرور/ماشین از این قبیل (مثل سرور ب، سرور ج و ….) را برای سرور هدف خود خریداری می کردیم. در چنین شرایطی ما سرورهای زیادی داریم که کد ما در آن اجرا می شود. در اینجا، سوال اصلی این است که چه ارتباطی بین HTTP و DNS وجود دارد؛ یعنی کاربری بنام آلیس یا یک ربات جستجوگر، آدرس یک وب سایت مثل www.popularwebsite.com را باید روی کدام سرور بزند و در نهایت به کدام سرور متصل می شود؟
خوب. اساساً زمانی که چندین سرور داریم و درخواست داریم تا بار ما، درخواست HTTP ورودی را بین تمام این سرورهای وب (سرور الف، ب، ج و …) توزیع کند، اساساً نمیخواهیم که فشار و درخواست های ورودی تنها بر روی یکی از سرورها قرار گرفته و باقی سرورها بار چندانی را به دوش نگیرند. در واقع دقیقاً برای این منظور است که ما یک تعادل کننده بار (Loan Balancer) داریم. فعلاً این مفهوم را مثل یک جعبه سیاه هواپیما در نظر بگیرید که وظیفه آن توزیع بار یا درخواست های HTTP ورودی بین سرورهای وب است.
اما سوال اساسی دیگر این است که یک متعادل کننده بار چگونه این موضوع را اجرایی می سازد؟ یعنی اگر وارد نشانی آدرسی مثل www.popularwebsite.com شویم، کدام یک از وب سرورهای الف، ب، ج و … به درخواست ما پاسخ خواهند داد؟
مطلب مفید: تفاوت صرافی های متمرکز و غیر متمرکز
کاری که در اینجا میتوانیم انجام دهیم این است که آدرس IP عمومی متعادلکننده بار (یعنی 74.0.126.28، مطابق تصویر فوق) را در معرض DNS قرار داده و در این صورت، سرورها/گرههای وب دیگر نیازی به داشتن آدرس IP عمومی خود نخواهند داشت. در حقیقت آنها یک آدرس IP خصوصی دارند که تنها جهت متعادل کننده بار و نه برای جهان خارج از سرور، شناخته شده است تا بدین ترتیب افراد سودجود بطور مستقیم با آنها تماس نگیرند. علاوه بر این، تعداد IPV4 های در دسترس در سطح دنیا در حال اتمام بوده و دریافت این دسته از آی پی ها دشوار و پرهزینه است. بنابراین داشتن یک آدرس IP خصوصی مرتبط با این گره ها که فقط برای متعادل کننده بار شناخته شده باشد، یک امتیاز مثبت بوده و متعادل کننده بار درخواست های دریافتی را به این گره ها هدایت خواهد کرد.
نحوه تصمیم گیری متعادل کننده بار
سوال مهمی که اینجا با آن روبرو میشویم این است که اساساً متعادل کننده بار چگونه تصمیم می گیرد که داده ها را از سرور بک اند (backend) دریافت کند؟ یا اینکه متعادل کننده بار چگونه تصمیم می گیرد که کدام یک از این گره ها فرصت انجام درخواست دریافتی را خواهند داشت؟
اساساً وقتی که درخواست به متعادل کننده بار می رسد، می تواند در مورد عوامل مختلفی تصمیم بگیرد که بر اساس آن درخواست به سرور الف، ب، ج و … ارسال شود. این یعنی متعادل کننده بار بررسی می کند که هرکدام از سرورها تا چه حد مشغول هستند و سپس تصمیم میگیرد که درخواست به کدام یک از آنها برسد.
اساساً تمامی این وب سرورها از محتوایی یکسان (کدهای مشابهی که در آنها اجرا می شود) برخوردار هستند. ما در اینجا به افزونگی دست یافتهایم اما نقطه ضعف این است که قبلاً فقط به دیسکی با اندازه n نیاز داشتیم و اکنون به تعداد سرورها به دیسک هایی با اندازه n نیاز خواهیم داشت. پس این بهایی است که برای داشتن این افزونگی یا مقیاس پذیری سرور افقی باید پرداخت کنیم.
از طرفی رویکرد دیگر این است که اجازه دهیم تا سرور الف، تنها حاوی فایلهای تصویری باشد و سرور ب با فایلهای HTTP و سرور ج فایل های ویدئویی. در نتیجه، در این سناریو میتوانیم بار بیشتری را روی سرور ویدیو یعنی سرور ج داشته باشیم.
علاوه بر این، یک رویکرد اکتشافی تر می تواند یک دور نوبتی (Round-robin) ساده باشد؛ یعنی اولین باری که بر روی سرور متعادل کننده بار کلیک می کینم، سرور الف را برگردانده و در دفعه بعد، سرور ب و دفعه بعد نیز سرور ج و به همین ترتیب. در حقیقت این بهایی است که ما در اینجا می پردازیم و این بها این است که شاید یک سرور به علت دریافت حجمی بالا و بیش از حد از کاربران، دچار مشکل شود. علت بروز این مشکل این است که الگوریتم دور نوبتی درخواست ها را به همان سرور اولی ارسال می کند و آن را بیش از حد سنگین می کند، که طبیعتاً این موضوع به هیچ وجه مطلوب نخواهد بود.
اشکال دیگر این است که به علت ذخیره سازی، ما به ارسال بار به یک سرور بخصوص ادامه می دهیم؛ چراکه نیازی نیست مرورگر هر بار که روی پیوند کلیک می کنید همان درخواست DNS را ارسال کند، زیرا با این کار چند میلی ثانیه زمان از دست خواهد رفت و در حجم بالایی از درخواست ها، این زمان بسیار زیادی خواهد بود. نتیجتاً اینکه سیستم عامل و مرورگر این پاسخ ها را جهت جلوگیری از این جستجوها در حافظه پنهان (Cache) نگه داری می کنند.
اما رویکردی بهتر می تواند این باشد که به متعادل کننده بار اجازه دهیم تا تصمیم بگیرد که کدام سرور با استفاده از هر روش اکتشافی، چه دور رابین (دور یک طرفه) و چه عامل تصادفی دیگر، درخواست خود را ارسال کند.
حقیقتاً یکی از مواردی که امکان دارد تا اشتباه پیش برود، جلسه (session) است. چرا؟ اساساً یادآوری جلسه معمولاً مختص یک ماشین خاص است و در سیستم عامل لینوکس، جلسات به صورت فایل متنی در آدرس /temp ذخیره می شوند. حال فرض کنید که جلسه ما بر روی /temp از سرورس الف بنشیند و اگر درخواست های ما به سرور ب یا ج ارسال شود، چه اتفاقی رخ خواهد داد؟ در حقیقت از ما خواسته خواهد شد که مجدداً وارد شویم و ما اطلاع نداریم که چرا این اتفاق دوباره و دوباره رخ خواهد داد. در واقع این سناریو در مورد وب سایت های مربوط به کسب و کار الکترونیکی یا درگاه های پرداخت، شدیداً شکست خواهد خورد.
راه حل
اما راه حل نهایی این است: اگر بتوانیم یک فایل سرور خارجی (مثل یک درایو خارجی عظیم که به همه سرورها متصل باشد)، همه سرورها می توانند حالت خود را با یکدیگر به اشتراک بگذارند. حال نگرانی بعدی این است که در چنین شرایطی ما افزونگی بسیار خوبی در مدل سرور خود خواهیم داشت؛ ولی به محض اینکه یک پایگاه داده یا سرور را برای جلسات خود معرفی کنیم و این سرورها از بین بروند، به نظر می رسد که مجدداً با شکست روبرو خواهیم شد.
تا اینجای کار ما مشکل وضعیت مشترک (shared state) را برطرف کردیم، اما برخی از استحکامات شبکه را قربانی برخی از افزونگی ها کرده ایم. حالا چگونه مشکل این استحکامات را برطرف کنیم؟ پیش از آنکه به این مشکل بپردازیم، بیایید در مورد نحوه اجرای یک متعادل کننده بار بحث کنیم؟
اساساً این نوع از متعادل کننده های بار با استفاده از نرمافزارها و سختافزارهای مختلفی که شامل ELB (مثل AWS) و HAproxy و سختافزارهایی مثل Citrix و Cisco اجرا میشوند، که اکثریت آنها به نسبت کارایی که دارند بسیار گران قیمت هستند.
موارد مورد نیاز جهت ایجاد یک وب سرویس مقیاس پذیر
در ادامه قصد داریم توضیح دهم که جهت ایجاد یک وب سرویس که به صورت گسترده مقیاس پذیر است، به چه چیزهایی لازم است؟
همانطور که دیدیم، تا اینجا برنامه ما به شدت مقیاس پذیر شده است و توان پردازش درخواست های همزمان بسیار زیادی دارد، ولی شاهد این خواهیم بود که به مرور زمان، سرور ما کند و کندتر می شود و علت این موضوع نیز مفهومی نیست به جز MySQL.
رفع کندی تدریجی سرور
اساساً 2 راه حل کلی برای حل این مشکل وجود دارد. اولین راه حل به ادامه اجرای MySql ما ادامه داده و کاری را انجام می دهد که اصطلاحاً به آن شاردینگ (sharding) می گوییم. اما مشکل این راه حل این است که شدیداً هزینه بر بوده و البته که برای اجرا نیازمند زمان بسیار زیادی هستند. اما راه حل دیگر این است که به NoSQL رفته یا بوسیله SQL DB خود به شکل یک NoSQL رفتار کنیم؛ چراکه NoSql مقیاس پذیری سرور بیشتری داشته و البته اجرای آن نیز آسانتر است. اما آیا انجام این کار مشکل را حل کرده و باعث می شود تا برنامه با سرعت بیشتری اجرا شود؟ پاسخ کماکان منفی است. اینجا است که به سراغ حافظه پنهان (Cache) می رویم.
هم اکنون ما قادر هستیم تا چندین ترابایت از داده ها را در حافظه خود ذخیره کنیم، ولی کاربران ما کماکان از کند بودن اجرای درخواستهای خود در صفحات سرور ما رنج میبرند. خب. ما با برای حل این مشکل چه کاری می توانیم انجام دهیم؟ پاسخ کچ کردن در حافظه (Memcache یا Redis) است.
اساساً کچ یک ذخیرهسازی ساده با ارزش کلیدی (key-value) است و به عنوان یک لایه بافر (buffering layer) میان برنامه و ذخیرهسازی داده ها عمل کرده و هر وقت که برنامه مجبور به خواندن داده ها باشد، ابتدا آنها را از حافظه پنهان خوانده و تنها در صورت عدم وجود آنها در این حافظه، فرایند جستجو را از بین داده های ذخیره شده ما انجام می دهد. در حقیقت حافظه پنهان ما تمام مجموعه داده ها را در RAM ذخیره کرده و درخواست ما را با سرعتی سریع ارائه می دهد. بطور کلی مواردی که میتوانیم آنها را در حافظه پنهان ذخیره کنیم عبارتند از جلسات کاربر (sessions)، جریانهای فعالیت (activity streams)، مقالات وبلاگ که کاملاً رندر شده باشد و بسیاری موارد دیگر.
مشکل ناهمزمانی
تا بدین جای کار ما اکثر مشکلات سرور خود را برطرف ساخته ایم و هم اکنون سیستم ما به صورت افقی کاملاً مقیاس پذیر شده است و می تواند درخواست های زیادی را با سرعتی بالا پردازش کند. با این وجود، باز هم این امکان وجود دارد تا با مشکلاتی مواجه شویم. بعنوان مثال یکی از کاربران قصد دارد تا یک کار محاسباتی فشرده را در وبسایت انجام دهد که مثلاً به 10 دقیقه زمان نیاز خواهد داشت. در اینجا است که وضعیت لطفاً کمی صبر کنید (please wait) رخ می دهد که همان مشکل ناهمزمانی (asynchronism) است.
در اینجا، به عنوان یک راه حل کلی، می توان محتوای پویا (dynamic) را به محتوایی ثابت (static) تبدیل کرد. در حقیقت این پیش محاسبه در داده های کلی می تواند وب سایت ها را شدیداً بهبود بخشیده و آن را کارآمدتر و مقیاس پذیرتر سازد. از طرفی می توان از یک شبکه تحویل محتوا (CDN) استفاده کرد تا صفحات HTML را از پیش رندر کند.
از طرفی، راه حل دیگر نیز RabbitMQ است. در واقع RabbitMQ جزأ سیستم هایی است که به پیاده سازی پردازش غیر همگام کمک می کند. اساساً ایده اصلی این است که یک صف از وظایف یا مشاغلی داشته باشید تا یک کاربر سرور بتواند به راحتی آنها را پردازش کند. اما اگر این فرایند زمان بر بود، باید سعی کنیم تا آن را به صورت ناهمزمان انجام دهیم و بدین شکل می توانیم مشکل ناهمزمانی سرور را نیز برطرف سازیم.

{kind=link}